本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
数据传输服务DTS(Data Transmission Service)支持将MongoDB的数据同步到AnalyticDB PostgreSQL版实例中。本文以云数据库MongoDB版(副本集架构)为源,为您介绍同步操作的步骤。
前提条件
已创建存储空间大于源云数据库MongoDB版实例已占用存储空间的目标AnalyticDB PostgreSQL版实例。创建方法,请参见创建实例。
说明建议目标实例的存储空间比源数据库已使用的存储空间大10%。
已在目标AnalyticDB PostgreSQL版实例中创建用于接收数据的数据库、Schema、具有主键列的表。创建方法,请参见SQL语法。
重要请务必确保目标表的数据类型与源MongoDB的数据兼容。例如,若MongoDB中的
_id为ObjectId类型,则对应AnalyticDB PostgreSQL版实例中数据类型需为varchar。AnalyticDB PostgreSQL版实例中目标表的列名不能为_id和_value。
若源为分片集群架构的云数据库MongoDB版,则还需为所有Shard节点申请连接地址,且各Shard的账号和密码需保持一致。申请方法,请参见申请Shard或ConfigServer节点连接地址。
注意事项
类型 | 说明 |
源库限制 |
|
其他限制 |
|
费用说明
同步类型 | 链路配置费用 |
全量数据同步 | 不收费。 |
增量数据同步 | 收费,详情请参见计费概述。 |
同步类型说明
同步类型 | 说明 |
全量同步 | 将源云数据库MongoDB版同步对象的存量数据全部同步到目标AnalyticDB PostgreSQL版实例中。 |
增量同步 | 在全量同步的基础上,将源云数据库MongoDB版的增量更新同步到目标AnalyticDB PostgreSQL版实例中。 说明
|
数据库账号的权限要求
数据库 | 所需权限 | 账号创建及授权方式 |
源云数据库MongoDB版 | 待同步库、admin库和local库的read权限。 | |
目标AnalyticDB PostgreSQL版 | 目标库的读写权限。 | 说明 您可以使用初始账号或具备RDS_SUPERUSER权限的账号。 |
操作步骤
进入目标地域的同步任务列表页面(二选一)。
通过DTS控制台进入
登录数据传输服务DTS控制台。
在左侧导航栏,单击数据同步。
在页面左上角,选择同步实例所属地域。
通过DMS控制台进入
说明实际操作可能会因DMS的模式和布局不同,而有所差异。更多信息,请参见极简模式控制台和自定义DMS界面布局与样式。
登录DMS数据管理服务。
在顶部菜单栏中,选择。
在同步任务右侧,选择同步实例所属地域。
单击创建任务,进入任务配置页面。
可选:在页面右上角,单击试用新版配置页。
说明若您已进入新版配置页(页面右上角的按钮为返回旧版配置页),则无需执行此操作。
新版配置页和旧版配置页部分参数有差异,建议使用新版配置页。
配置源库及目标库信息。
类别
配置
说明
无
任务名称
DTS会自动生成一个任务名称,建议配置具有业务意义的名称(无唯一性要求),便于后续识别。
源库信息
选择已有连接信息
您可以按实际需求,选择是否使用已有数据库实例。
如使用已有实例,下方数据库信息将自动填入,您无需重复输入。
如不使用已有实例,您需要配置下方的数据库信息。
说明您可以在数据连接管理页面或新版配置页面,将数据库录入DTS。更多信息,请参见数据连接管理。
DMS控制台的配置项为选择DMS数据库实例,您可以单击新增DMS数据库实例或在控制台首页将数据库录入DMS。更多信息,请参见云数据库录入和他云/自建数据库录入。
数据库类型
选择MongoDB。
接入方式
选择云实例。
实例地区
选择源云数据库MongoDB版所属的地域。
是否跨阿里云账号
本示例使用当前阿里云账号下的数据库实例,需选择不跨账号。
架构类型
本示例选择副本集架构。
说明若您的源云数据库MongoDB版为分片集群架构,您还需要填写Shard账号和Shard密码。
迁移方式
请根据实际情况,选择增量数据同步的方式。
Oplog(推荐):
若源库已开启Oplog日志,则支持此选项。
说明本地自建MongoDB和云数据库MongoDB版默认已开启Oplog日志,且使用此方式同步增量数据时增量同步任务的延迟较小(拉取日志的速度较快),因此推荐选择Oplog。
ChangeStream:
若源库已开启变更流(Change Streams),则支持此选项。
说明源库为Amazon DocumentDB(非弹性集群)时,仅支持选择ChangeStream。
源库架构类型选择为分片集群架构,无需填写Shard账号和Shard密码。
实例ID
选择源云数据库MongoDB版的实例ID。
鉴权数据库名称
填入源云数据库MongoDB版实例中数据库账号所属的数据库名称,若未修改过则为默认的admin。
数据库账号
填入源云数据库MongoDB版的数据库账号,权限要求请参见数据库账号的权限要求。
数据库密码
填入该数据库账号对应的密码。
连接方式
DTS支持非加密连接、SSL安全连接和Mongo Atlas SSL三种连接方式。连接方式的选项与接入方式和架构类型有关,请以控制台为准。
说明架构类型为分片集群架构,且迁移方式为Oplog的MongoDB数据库,不支持SSL安全连接。
若源库为自建(接入方式不为云实例)副本集架构的MongoDB数据库,并且选择了SSL安全连接,DTS还支持上传CA证书对连接进行校验。
目标库信息
选择已有连接信息
您可以按实际需求,选择是否使用已有数据库实例。
如使用已有实例,下方数据库信息将自动填入,您无需重复输入。
如不使用已有实例,您需要配置下方的数据库信息。
说明您可以在数据连接管理页面或新版配置页面,将数据库录入DTS。更多信息,请参见数据连接管理。
DMS控制台的配置项为选择DMS数据库实例,您可以单击新增DMS数据库实例或在控制台首页将数据库录入DMS。更多信息,请参见云数据库录入和他云/自建数据库录入。
数据库类型
选择AnalyticDB PostgreSQL。
接入方式
选择云实例。
实例地区
选择目标AnalyticDB PostgreSQL版实例所属的地域。
实例ID
选择目标AnalyticDB PostgreSQL版实例的名ID。
数据库名称
填入目标AnalyticDB PostgreSQL版实例中用于接收同步对象的数据库名称。
数据库账号
填入目标AnalyticDB PostgreSQL版实例的数据库账号,权限要求请参见数据库账号的权限要求。
数据库密码
填入该数据库账号对应的密码。
配置完成后,在页面下方单击测试连接以进行下一步。
说明请确保DTS服务的IP地址段能够被自动或手动添加至源库和目标库的安全设置中,以允许DTS服务器的访问。更多信息,请参见添加DTS服务器的IP地址段。
若源库或目标库为自建数据库(接入方式不是云实例),则还需要在弹出的DTS服务器访问授权对话框单击测试连接。
配置任务对象。
在对象配置页面,配置待同步的对象。
配置
说明
同步类型
固定选中增量同步。仅支持选中全量同步,不支持库表结构同步。预检查完成后,DTS会将源实例中待同步对象的数据在目标集群中初始化,作为后续增量同步数据的基线数据。
实例级别选择所需同步的DDL和DML
按实例级别选择需要增量同步的操作。
说明如需按集合级别选择需要增量同步的操作,请在已选择对象中右键单击同步对象,然后在弹跳框中勾选。
目标已存在表的处理模式
预检查并报错拦截:检查目标数据库中是否有同名的表。如果目标数据库中没有同名的表,则通过该检查项目;如果目标数据库中有同名的表,则在预检查阶段提示错误,数据同步任务不会被启动。
说明如果目标库中同名的表不方便删除或重命名,您可以更改该表在目标库中的名称,请参见库表列名映射。
忽略报错并继续执行:跳过目标数据库中是否有同名表的检查项。
警告选择为忽略报错并继续执行,可能导致数据不一致,给业务带来风险,例如:
表结构一致的情况下,如在目标库遇到与源库主键或唯一键的值相同的记录:
全量期间,DTS会保留目标集群中的该条记录,即源库中的该条记录不会同步至目标数据库中。
增量期间,DTS不会保留目标集群中的该条记录,即源库中的该条记录会覆盖至目标数据库中。
表结构不一致的情况下,可能会导致无法初始化数据、只能同步部分列的数据或同步失败,请谨慎操作。
源库对象
在源库对象框中单击待同步对象,然后单击
 将其移动至已选择对象框。说明
将其移动至已选择对象框。说明同步对象的选择粒度为集合。
已选择对象
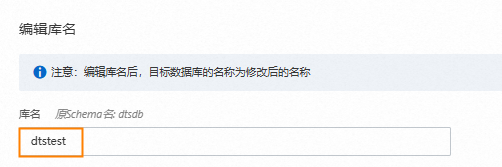
编辑库名映射。
右键单击已选择对象中的待同步集合所属的数据库。
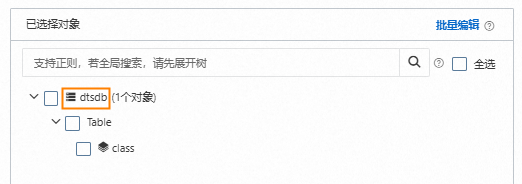
将库名修改为目标AnalyticDB PostgreSQL版实例中接收数据的Schema名称。
可选:在勾选所需同步的DML&DDL操作区域选择所需增量同步的操作。

单击确定。
编辑表名映射。
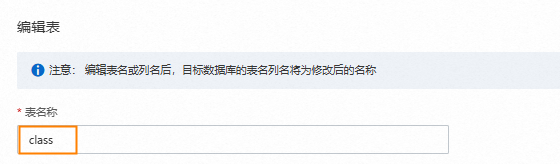
右键单击已选择对象中的待同步的集合。
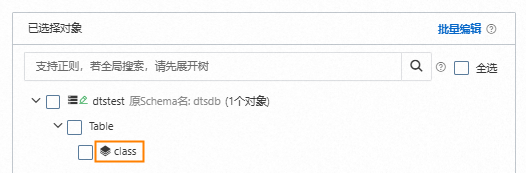
将表名称修改为目标AnalyticDB PostgreSQL版实例中接收数据的表名称。
可选:设置过滤条件,设置方法请参见设置过滤条件。

可选:在勾选所需同步的DML&DDL操作区域选择所需增量同步的操作。

配置MongoDB中需要同步的字段(Field)。
单击下一步高级配置,进行高级参数配置。
配置
说明
选择调度该任务的专属集群
DTS默认将任务调度到共享集群上,您无需选择。若您希望任务更加稳定,可以购买专属集群来运行DTS同步任务。更多信息,请参见什么是DTS专属集群。
源库、目标库无法连接后的重试时间
在同步任务启动后,若源库或目标库连接失败则DTS会报错,并会立即进行持续的重试连接,默认持续重试时间为720分钟,您也可以在取值范围(10~1440分钟)内自定义重试时间,建议设置30分钟以上。如果DTS在设置的重试时间内重新连接上源库、目标库,同步任务将自动恢复。否则,同步任务将会失败。
说明针对同源或者同目标的多个DTS实例,如DTS实例A和DTS实例B,设置网络重试时间时A设置30分钟,B设置60分钟,则重试时间以低的30分钟为准。
由于连接重试期间,DTS将收取任务运行费用,建议您根据业务需要自定义重试时间,或者在源和目标库实例释放后尽快释放DTS实例。
源库、目标库出现其他问题后的重试时间
在同步任务启动后,若源库或目标库出现非连接性的其他问题(如DDL或DML执行异常),则DTS会报错并会立即进行持续的重试操作,默认持续重试时间为10分钟,您也可以在取值范围(1~1440分钟)内自定义重试时间,建议设置10分钟以上。如果DTS在设置的重试时间内相关操作执行成功,同步任务将自动恢复。否则,同步任务将会失败。
重要源库、目标库出现其他问题后的重试时间的值需要小于源库、目标库无法连接后的重试时间的值。
是否限制全量迁移速率
在全量同步阶段,DTS将占用源库和目标库一定的读写资源,可能会导致数据库的负载上升。您可以根据实际情况,选择是否对全量同步任务进行限速设置(设置每秒查询源库的速率QPS、每秒全量迁移的行数RPS和每秒全量迁移的数据量(MB)BPS),以缓解目标库的压力。
说明仅当同步类型选择了全量同步时才可以配置。
同一张表内主键_id的数据类型是否唯一
待同步的数据中,同一个集合内主键
_id的数据类型是否唯一。说明仅当同步类型选择了全量同步时才可以配置。
是:唯一。在全量同步阶段,DTS将不会扫描源库待同步数据中主键的数据类型。
否:不唯一。在全量同步阶段,DTS将扫描源库待同步数据中主键的数据类型。
是否限制增量同步速率
您也可以根据实际情况,选择是否对增量同步任务进行限速设置(设置每秒增量同步的行数RPS和每秒增量同步的数据量(MB)BPS),以缓解目标库的压力。
环境标签
您可以根据实际情况,选择用于标识实例的环境标签。本示例无需选择。
配置ETL功能
选择是否配置ETL功能。关于ETL的更多信息,请参见什么是ETL。
是:配置ETL功能,并在文本框中填写数据处理语句,详情请参见在DTS迁移或同步任务中配置ETL。
否:不配置ETL功能。
监控告警
是否设置告警,当同步失败或延迟超过阈值后,将通知告警联系人。
不设置:不设置告警。
设置:设置告警,您还需要设置告警阈值和告警联系人。更多信息,请参见在配置任务过程中配置监控告警。
保存任务并进行预检查。
若您需要查看调用API接口配置该实例时的参数信息,请将鼠标光标移动至下一步保存任务并预检查按钮上,然后单击气泡中的预览OpenAPI参数。
若您无需查看或已完成查看API参数,请单击页面下方的下一步保存任务并预检查。
说明在同步作业正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动同步作业。
如果预检查失败,请单击失败检查项后的查看详情,并根据提示修复后重新进行预检查。
如果预检查产生警告:
对于不可以忽略的检查项,请单击失败检查项后的查看详情,并根据提示修复后重新进行预检查。
对于可以忽略无需修复的检查项,您可以依次单击点击确认告警详情、确认屏蔽、确定、重新进行预检查,跳过告警检查项重新进行预检查。如果选择屏蔽告警检查项,可能会导致数据不一致等问题,给业务带来风险。
购买实例。
预检查通过率显示为100%时,单击下一步购买。
在购买页面,选择数据同步实例的计费方式、链路规格,详细说明请参见下表。
类别
参数
说明
信息配置
计费方式
预付费(包年包月):在新建实例时支付费用。适合长期需求,价格比按量付费更实惠,且购买时长越长,折扣越多。
后付费(按量付费):按小时扣费。适合短期需求,用完可立即释放实例,节省费用。
资源组配置
实例所属的资源组,默认为default resource group。更多信息,请参见什么是资源管理。
链路规格
DTS为您提供了不同性能的同步规格,同步链路规格的不同会影响同步速率,您可以根据业务场景进行选择。更多信息,请参见数据同步链路规格说明。
订购时长
在预付费模式下,选择包年包月实例的时长和数量,包月可选择1~9个月,包年可选择1年、2年、3年和5年。
说明该选项仅在付费类型为预付费时出现。
配置完成后,阅读并勾选《数据传输(按量付费)服务条款》。
单击购买并启动,并在弹出的确认对话框,单击确定。
您可在数据同步界面查看具体任务进度。

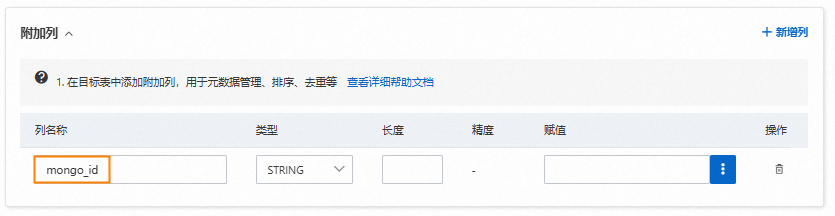


赋值配置示例
源MongoDB的数据结构
{
"_id":"62cd344c85c1ea6a2a9f****",
"person":{
"name":"neo",
"age":26,
"sex":"male"
}
}目标AnalyticDB PostgreSQL版的表结构
列名称 | 类型 |
mongo_id | varchar 说明 主键列。 |
person_name | varchar |
person_age | decimal |
新增列配置
请按照层级关系正确配置bson_value()表达式,否则可能会导致数据丢失或任务失败。例如,若您配置的表达式为bson_value("person"),DTS将无法把源端person的子字段(name、age、sex)的增量变更数据写入到目标端。
列名称 | 类型 | 赋值 |
mongo_id | STRING | bson_value("_id") |
person_name | STRING | bson_value("person","name") |
person_age | DECIMAL | bson_value("person","age") |